جدید کار با فایلهای csv در پایتون
خلاصه ای درباره فایلهای csv
یکی از محبوب ترین فرمت ها برای تبادل داده، فرمت CSV است. فایل CSV نوعی فایل متنی ساده است که از ساختار خاصی برای مرتب کردن داده های جدولی استفاده می کند. فایلهای CSV از کاما برای جدا کردن هر مقدار داده خاص استفاده میکنند.
به علت ساختار ساده و متنی فایلهای csv اکثر زبانهای برنامه نویسی می توانند به طور مستقیم با آنها کار کنند.
کتابخانه csv در پایتون
کتابخانه csv شامل اشیا و کدهای دیگر برای خواندن، نوشتن و پردازش داده ها از و به فایل های CSV است. بنابراین لازم هست در ابتدا این کتابخانه را در برنامه مان فراخوانی کنیم:
import csv
ایجاد فایل csv و نوشتن اطلاعات در آن
روند کار به این صورت هست که ابتدا یک فایل در حالت نوشتنی باز می کنیم و بعد یک شی writer برای این فایل ایجاد می کنیم و سپس داده ها را در سطرهای فایل وارد می نماییم:
import csv
import os
currentDir=os.path.dirname(os.path.abspath(__file__))
with open(currentDir + "\mycsv.csv", 'w') as myfile:
mywriter = csv.writer(myfile)
mywriter.writerow(["Name", "Employee Number", "Salary"])
mywriter.writerow(["Sara", "LQ370956", 65000000])
mywriter.writerow(["Kamran", "MB446589", 60000000])
در برنامه بالا ابتدا کتابخانه csv و در خط بعد کتابخانه os فراخوانی شده اند. با استفاده از کتابخانه os برای پیدا کردن آدرسی که برنامه در آن قرار دارد استفاده می کنیم. در خط 3 آدرس دایرکتوری جاری را در currentDir ذخیره می کنیم.
در خط 4 یک فایل در حالت نوشتنی باز می کنیم و درون برنامه نام آن را myfile می گذاریم. نام اصلی فایل ما mycsv.csv خواهد بود که در ترکیب با آدرس جاری ( که در خط قبل آن را در currentDir ذخیره کردیم ) مشخص می کند که دقیقا این فایل در کدام مسیر قرار دارد.
پارامتر ‘w’ به برنامه می گوید که فایل در حالت نوشتنی باز شود. و اگر newline=’’ را ننویسیم بین هر دو سطر یک سطر خالی ایجاد خواهد شد.
در خط 5 با استفاده از دستور csv.writer محتوای یک شی از نوع writer ایجاد می کنیم با نام mywriter که بتوان با استفاده از آن داده ها را در فایل myfile ( در واقع همان mycsv ) وارد کرد.
برای اضافه کردن یک سطر به فایل csv از دستور writerow استفاده می کنیم. فرض کنید می خواهیم اطلاعات نام کارمندان و شماره پرسنلی و حقوق آنها را در فایل ذخیره کنیم. در خط 6 یک سطر درست می کنیم و عنوان هر ستون را در آن وارد می کنیم.
سپس در دو خط بعد اطلاعات دو نفر از کارمندان فرضی را وارد می کنیم. با اجرای برنامه خواهید دید که یک فایل با نام mycsv در همان فایلی که برنامه را ذخیره کرده اید ایجاد شده است و می توانید با نرم افزار اکسل آن را باز و محتویات آن را مشاهده کنید:
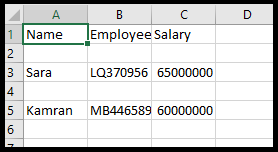
به وضوح مشخص است که بین هر دو سطر یک ردیف خالی قرار دارد. برای اینکه این مشکل رفع بشود باید خط 4 را به این شکل تغییر دهیم:
with open(currentDir + "\mycsv2.csv", 'a', newline='') as myfile:
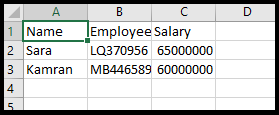
در واقع با اضافه کردن خصوصیت newline= ‘ ‘ کاری می کنیم که پس از نوشته شدن یک سطر، یک ردیف خالی ایجاد نشود. نتیجه را می توانید در شکل زیر ببینید:
جلوگیری از پاک شدن فایل قبلی با استفاده از حالت append
دقت کنید که با اجرای برنامه بالا، اگر از قبل فایلی با نام mycsv وجود داشته باشد، محتویات آن پاک خواهد شد و داده هایی که در برنامه وارد کرده ایم در آن نوشته می شود.
برای اینکه موقع باز کردن فایل، محتوای قبلی از بین نرود و داده ها به سطرهای قبلی اضافه شود باید موقع باز کردن فایل ( خط 4 برنامه بالا ) به جای ‘w’ از ‘a’ استفاده کنید که به معنی append است.
نوشتن در فایل csv با روش موثرتر
حالا قصد داریم کاری را که انجام دادیم با روش مناسب تری با یک برنامه دیگر انجام دهیم:
import csv
import os
myheader=("Name", "Employee Number", "Salary")
mydata=(["Sara", "LQ370956", 65000000],["Kamran", "MB446589", 60000000])
currentDir=os.path.dirname(os.path.abspath(__file__))
with open(currentDir + "\mycsv2.csv", 'w', newline='') as myfile:
mywriter = csv.writer(myfile)
mywriter.writerow(myheader)
mywriter.writerows(mydata)
در خط 3 عنوان ستون ها را در یک لیست با نام myheader قرار می دهیم و در خط 4 داده های کارمندان را در لیستی به نام mydata ذخیره می کنیم.
می بینید که در ادامه ساختار برنامه جدید با برنامه قبل تفاوت چندانی ندارد. در خط 8 به جای اینکه عنوان ستونها را به طور مستقیم در فایل بنویسیم ، آنها را از طریق myheader وارد می کنیم. در خط بعدی به جای اینکه هر سطر را هربار با استفاده از یک دستور writerow وارد کنیم، همه آنها را در mydata ذخیره کرده ایم و با استفاده از writerows آنها را در سطرهای بعدی می نویسیم. با این دستور می توتن چندین سطر را به صورت هم زمان در فایل csv نوشت.
پس از اجرای برنامه خواهید دید که محتوای فایل mycsv2 با فایل mycsv که در برنامه قبلی ایجاد کردیم تفاوتی ندارد.
خواندن فایلهای csv در پایتون
حالا بیایید یک فایل csv به نام mycsv3 با یک برنامه پایتون دیگر باز کنیم و محتوای آن را مشاهده کنیم.
اطلاعات داخل فایل mycsv3 به این صورت هست:
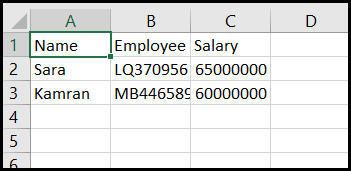
برنامه به این صورت نوشته می شود:
import csv
import os
currentDir=os.path.dirname(os.path.abspath(__file__))
with open(currentDir + "\mycsv2.csv", 'r') as myfile:
myreader = csv.reader(myfile, delimiter=",")
for row in myreader:
print(row)
ابتدا کتابخانه csv و os را فراخوانی و در خط 3 آدرس جاری را استخراج می کنیم. در خط 4 فایل mycsv2.csv را باز می کنیم و آن را myfile می نامیم. همان طور که می بینید از ‘r’ استفاده شده که در نتیجه فایل در حالت خواندنی باز می شود.
سپس در خط 5 یک شی reader به نام myreader ایجاد می کنیم و با استفاده از csv.reader فایل myfile را در این شی می ریزیم. همچنین delimiter را برابر با “ , “ قرار می دهیم تا هر سلول به صورت جداگانه به عنوان محتوای یک سلول در نظر گرفته شود.
در خط بعدی یک حلقه for قرار می دهیم که تا زمانی که در این شی سطری موجود باشد حلقه ادامه پیدا می کند و هر سطر را داخل این حلقه نمایش می دهیم.
با اجرای برنامه نتیجه را در ترمینال به این صورت مشاهده خواهید کرد:
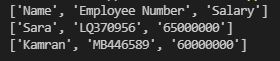
ذخیره سطرهای فایل csv در لیست
اما اگر بخواهیم مقادیر را در جایی ذخیره کنیم یا بخواهیم مقدار یک سلول خاص را تغییر دهیم باید چکار کنیم؟ برای این کار برنامه بالا را به این شکل تغییر می دهیم:
import csv
import os
currentDir=os.path.dirname(os.path.abspath(__file__))
with open(currentDir + "\mycsv3.csv", 'r') as myfile:
myreader = csv.reader(myfile, delimiter=",")
myrows = list(myreader)
در واقع این برنامه تا خط 5 تفاوتی با برنامه قبل ندارد، اما در خط 6 شی myreader را تبدیل به لیست کرده و در myrows ذخیره کرده ایم.
حالا اگر بخواهیم مقدار یک سلول را عوض کنیم کافی است مقدار متناظر آن در لیست را عوض کنیم و بعد لیست را مجددا در فایل ذخیره کنیم.
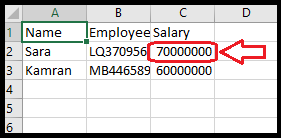
فرض کنید که حقوق سارا به 70000000 افزایش یافته است و می خواهیم فایل csv را به روز کنیم. برای این کار چند خط را به برنامه اضافه می کنیم:
import csv
import os
currentDir=os.path.dirname(os.path.abspath(__file__))
with open(currentDir + "\mycsv3.csv", 'r') as myfile:
myreader = csv.reader(myfile, delimiter=",")
myrows = list(myreader)
myrows[1][2]=70000000
with open(currentDir + "\mycsv4.csv", 'w', newline='') as myfile:
mywriter = csv.writer(myfile)
mywriter.writerows(myrows)
با توجه به اینکه اندیس لیستها از 0 شروع می شود وحقوق سارا در ستون سوم و سطر دوم قرار دارد، در خط 7 مقدار سلول مورد نظر را به 70000000 تغییر می دهیم. سپس یک فایل با نام mycsv4 در حالت نوشتنی باز می کنیم و یک شی از نوع writer ایجاد می کنیم.
سرانجام لیست را در این فایل جدید ذخیره می کنیم. با باز کردن این فایل csv خواهید دید که مقدار حقوق سارا تغییر کرده است: